|
ORAL PROBATOIRE METHODES D'AUTHENTIFICATION VOCALE D'UTILISATEURS DANS LES SYSTEMES INFORMATIQUES PAR GILLES
|
CONSERVATOIRE
NATIONAL DES ARTS ET METIERS
CENTRE
REGIONAL ASSOCIE DE STRASBOURG
ORAL
PROBATOIRE
présenté
en vue d’obtenir
Le
DIPLOME D’INGENIEUR C.N.A.M.
en
INFORMATIQUE
par
Gilles
------------------------------------------
Méthodes
d’authentification vocale d’utilisateurs
dans les systčmes informatiques
Soutenu
le 27 mai 2000
------------------------------------------
JURY
PRESIDENT : C. Kaiser
MEMBRES : J. Korczak, A. Napoli, S. Metzger, E. Maurice, J.L. Steffan
Sujet
Table de matičres
1.2. Le marché de la biométrie
1.3. Les domaines d’utilisation de la biométrie
1.4. Principe de fonctionnement et performance
1.5. L’authentification par « la voix »
2. L’Authentification Automatique du Locuteur (AAL)
2.2. Dépendance et Indépendance au texte
2.3. Evaluation des performances en AAL
3.1. Structure d’un systčme d’AAL
3.2.1. Paramčtres de l’analyse spectrale
3.2.3. Paramčtres exploitant la dynamique du signal de parole
3.2.4. Nouvelles paramétrisations
3.3.2. Méthodes connexionnistes
3.3.3. Modélisation multi-classes
3.3.4. Un point sur les performances actuelles
4. Analyse de produits commercialisés et de prototypes de recherche
4.2. BUYTEL Ltd et ITT INDUSTRIES
4.8. Tests des produits sélectionnés
5. Problčmes et limites des systčmes actuels
5.1. Variabilité due au locuteur
5.2. Variabilité due aux conditions d’enregistrement et de transmission
6.
Quelques solutions aux problčmes de robustesse
6.1. Paramétrisations robustes
6.2. Ré-estimation ou adaptation des modčles
La croissance internationale des communications, tant en volume qu'en diversité (déplacements physiques, transactions financičres, accčs aux services...), implique le besoin de s'assurer de l'identité des individus. En effet, l'importance des enjeux peut motiver les fraudeurs ŕ mettre en échec les systčmes de sécurité existants.
Il existe donc un intéręt grandissant pour les systčmes électroniques d'identification et de reconnaissance. Leur dénominateur commun est le besoin d'un moyen simple, pratique, fiable et peu onéreux de vérifier l'identité d'une personne sans l'assistance d'un tiers. Le marché du contrôle d'accčs s'est ouvert avec la prolifération de systčmes, mais aucun ne se révčle efficace contre la fraude, car tous utilisent un identifiant externe tel que : badge/carte, clé, code, .…
Il est fréquent d'oublier un code d'accčs. Il existe d’ailleurs de nombreux bureaux oů les mots de passe sont notés dans des listes, ce qui représente une dangereuse faille dans la sécurité informatique de l’entreprise puisque toute confidentialité est alors perdue [Vnunet, 2000]. De męme, un badge ou une clé peuvent ętre, volés ou copiés par des personnes mal intentionnées.
Dans le domaine de l’informatique par exemple, le CLUSIF (Club de la Sécurité Informatique) évalue ŕ 7,8 millions de francs les pertes annuelles engendrées par les fraudes, les malveillances et les copies illicites de fichiers informatiques [Biométrie Online].
Le défaut commun ŕ tous les systčmes d'authentification est que l'on identifie un objet (code, carte...) et non la personne elle-męme.
Face ŕ la contrainte de l'authentification par « objets », la biométrie apporte simplicité et confort aux utilisateurs.
Cette discipline s’intéresse en effet ŕ l’analyse du comportement ainsi qu’ŕ l’analyse de la morphologie humaine et étudie, par des méthodes mathématiques (statistiques, probabilités), les variations biologiques des personnes.
Les moyens biométriques permettent donc une authentification sűre car ils sont basés sur l’individu lui-męme.
Il est alors indispensable de caractériser l’individu par une empreinte afin de le différencier des autres sans aucune ambiguďté ; cette empreinte est une clé codant l’identité d’une personne sans redondance ni variabilité. La plupart des indices biométriques, comme les empreintes digitales ou génétiques, répondent ŕ ces critčres [Besacier, 98].
Il en est différemment pour la voix dont la disposition ŕ varier est inscrite dans sa nature męme [Rossi, 89]. Si nous ne pouvons pas vraiment parler d’empreinte vocale, la variabilité d’une personne ŕ une autre démontre tout de męme les différences du signal de parole en fonction du locuteur.
Cette variabilité, utile pour différencier les locuteurs, est également mélangée ŕ d’autres types de variabilité - variabilité due au contenu linguistique, variabilité intra-locuteur (qui fait que la voix dépend aussi de l’état physique et émotionnel d’un individu), variabilité due aux conditions d’enregistrement du signal de parole (bruit ambiant, microphone utilisé, lignes de transmission) – qui peuvent rendre l’identification du locuteur plus difficile.
Malgré toutes ces difficultés apparentes, la voix reste un moyen biométrique intéressant ŕ exploiter car pratique et disponible via le réseau téléphonique, contrairement ŕ ses concurrents.
Nous vous présenterons donc dans un premier temps les différents moyens d’authentification biométrique, leurs marchés, leurs domaines d’utilisation, leurs principes de fonctionnement ainsi que leurs performances.
Nous étudierons ensuite de façon plus approfondie l’un des moyens d’authentification biométrique : la « voix », en la comparant aux autres moyens puis en présentant les différents niveaux d’authentification par la voix ainsi que leurs performances.
Puis nous aborderons la structure d’un systčme d’authentification par la voix, les diverses méthodes qui y sont attachées en établissant une taxonomie des méthodes utilisées.
Seront ensuite présentés des produits et prototypes de recherche en la matičre, une brčve description des sociétés qui les ont établis, le marché et les applications visés, ainsi que leurs caractéristiques. Quelques tests de produits sélectionnés vous seront alors exposés.
Nous conclurons enfin par les problčmes et les limites des systčmes actuels en suggérant quelques solutions.
Le mot Anglais « Biometric », utilisé pour définir « La mesure des éléments morphologiques des humains », est fréquemment traduit en français par « Biométrie ».
La définition de « Biométrie » donnée par le Petit Robert est une « science qui étudie ŕ l'aide de mathématiques (statistiques, probabilités) les variations biologiques ŕ l'intérieur d'un groupe déterminé ».
La biométrie est donc une discipline qui s'intéresse ŕ la mesure de caractéristiques physiques d'ętres vivants et ŕ leur traitement statistique. Lorsqu'il est question de mesurer des organismes humains, le terme anthropométrie est également utilisé.
Les termes "biométrie" et "biométrique" se rapportent donc ŕ des dispositifs destinés ŕ reconnaître des ętres humains ŕ partir de mesures effectuées automatiquement. L’authentification peut concerner le visage, la forme de la main, les empreintes digitales, l’iris, la rétine, la voix, …. Les possibilités sont illimitées.
Il existe 2 catégories de technologies biométriques :
ź d’une part les techniques d'analyse du comportement :
- la dynamique de la signature (la vitesse de déplacement du stylo, les accélérations, la pression exercée, l'inclinaison),
- la façon d'utiliser un clavier d'ordinateur (la pression exercée, la vitesse de frappe).
ź et d’autre part les techniques d'analyse de la morphologie humaine (empreintes digitales, forme de la main, traits du visage, dessin du réseau veineux de l'śil, la voix). Ces éléments ont l'avantage d'ętre stables dans la vie d'un individu et ne subissent pas autant les effets du stress par exemple, que l'on retrouve dans l'identification comportementale.
Le cadre juridique
Les systčmes biométriques permettent un traitement d'informations nominatives ; leur mise en oeuvre est soumise, en France, ŕ la loi n°78-17 du 6 janvier 1978, relative ŕ l'informatique, aux fichiers et aux libertés. Cette mise en oeuvre sur le territoire français est soumise ŕ l'autorisation de la commission nationale de l'informatique et des libertés (CNIL), ce qui garantit au public qu'il n'y a pas atteinte ŕ la vie privée, ou aux libertés individuelles ou publiques.
La biométrie et l’informatique
Dans le passé, le traitement automatique (informatisé) de l’authentification d'empreintes digitales nécessitait l'utilisation d'importants moyens matériels de traitement. Le coűt d'élaboration d'un tel systčme en cantonnait l'usage ŕ des applications spécifiques et ŕ des organismes trčs motivés qui y mettaient les moyens (systčme judiciaire, fichier national d'identité, contrôle d'accčs haute sécurité).
A présent, les microprocesseurs possčdent la puissance nécessaire ŕ un traitement de ce type et leur coűt ne cesse de décroître.
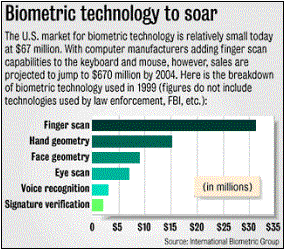
1.2. Le marché de la biométrie
|
Les ventes de logiciels de sécurité qui représentaient 3,1 milliards de dollars en 1998 ont progressé de 67% de 1996 ŕ 1997 et de plus de 55% en 1998. Le cabinet IDC estime que la croissance devrait se maintenir aux environs de 40% jusqu'en 2002, pour des ventes totales de 7,4 milliards de dollars. Pour le marché français de la sécurité des systčmes d'informations, IDC prévoit un triplement du chiffre d'affaires entre 1998 et 2002, passant de 1,180 milliards de francs ŕ 3,350 milliards de francs. Aux Etats-Unis, le marché de l'authentification biométrique double chaque année, passant de 25 millions de dollars de chiffre d'affaires en 1997 ŕ 50 millions en 1998, pour atteindre les 100 millions en 1999 [Biométrie Online] |
|
Ces chiffres restent modestes, mais plusieurs facteurs devraient participer au développement prochain de la biométrie, y compris en France.
Le marché de la sécurité informatique est encore atomisé, peu de fournisseurs peuvent prétendre offrir une gamme complčte de produits. Toutefois, les spécialistes estiment que ce marché est en pleine croissance et qu'il va également se concentrer.
En effet, Internet et le commerce électronique sont des marchés porteurs pour la sécurité, mais ils ne sont pas les seuls. Le télétravail, la mise ŕ dispositions d'informations aux clients et sous-traitants sont également des facteurs de risque pour les entreprises qui ouvrent leur systčme d'informations.
Le marché des produits d'authentification individuelle par l'approche biométrique est donc en forte croissance et la technologie dominante actuellement serait celle employant les empreintes digitales. La raison est simple : on a accepté depuis longtemps le fait que les empreintes digitales soient uniques pour un individu donné, et ce fait est supporté par des analyses de probabilité qui affirment que la probabilité théorique de retrouver deux configurations similaires sur les empreintes digitales de deux individus est de l'ordre de 10(-20) (équivalant ŕ une chance sur des milliards de milliards) [Biométrie Online].
Le GARTNER GROUP a publié en 1998 une liste des dix technologies clés ŕ suivre. Le résultat montre que parmi les systčmes biométriques, les empreintes digitales, l'śil et la forme du visage arrivent en tęte de liste ; vient ensuite l’authentification vocale.
Le marché en France
Du coté des utilisateurs ou clients potentiels, il n'y a plus de réticence et la demande est en forte croissance.
Les sollicitations les plus fréquentes ŕ ce jour concernent le remplacement du mot de passe par la biométrie ŕ l'ouverture d'un logiciel ainsi que le contrôle d'accčs aux locaux.
Des produits de ce type en provenance des USA existent déjŕ sur le marché, mais les utilisateurs préféreraient un produit européen pour ętre certain d'obtenir facilement et rapidement un soutien technique et plus particuličrement si l'utilisateur souhaite intégrer cette technologie au sein de sa propre application.
Les industriels compétents existent en Europe. Ils sont souvent pręts pour la production. En revanche, pour commercialiser ces produits ŕ des prix acceptables sur le marché, il faut que le volume de production soit important dčs le début de la commercialisation.
C'est lŕ que se situe le problčme européen pour ne pas dire français, il manque tout simplement l'engagement d'investisseurs pour soutenir ces entreprises dans la pénétration de ce marché qui émerge. Un marché qui n'est męme plus ŕ risque puisque la demande existe. Bien entendu, cette difficulté n'existe pas aux USA.
1.3. Les domaines d’utilisation de la biométrie
La liste des applications pouvant utiliser la biométrie pour contrôler un accčs (physique ou logique) peut ętre trčs longue. La taille de cette liste n'est limitée que par l'imagination de chacun dans son domaine d'activité [Biométrie Online].
ź contrôle d'accčs aux locaux,
- salle informatique,
- site sensible (service de recherche, site nucléaire).
ź systčmes d'informations,
- lancement du systčme d'exploitation,
- accčs au réseau,
- commerce électronique,
- transaction (financičre pour les banques, de données entre entreprises),
- tous les logiciels utilisant un mot de passe.
ź équipements de communication,
- terminaux d'accčs ŕ Internet,
- téléphones portables.
ź machines et équipements divers,
- coffre-fort avec serrure électronique,
- distributeur automatique de billets,
- casier sensible (club de tir, police),
- cantine d'entreprise (pour éviter l'utilisation d'un badge par une personne extérieure),
- casier de piscine (plus d'objet ŕ porter sur soi),
- contrôle des adhérents dans un club, carte de fidélité,
- contrôle des temps de présence,
- voiture (anti-démarrage).
ź état / administration,
- fichier judiciaire,
- titres d'identité (carte nationale d'identité, passeport, permis de conduire),
- services sociaux (sécurisation des rčglements),
- services municipaux (sécurisation des accčs aux écoles),
- systčme de vote électronique.
1.4. Principe de fonctionnement et performance
On peut décomposer le fonctionnement de l’authentification biométrique de la façon suivante : (figure 2)
1. capture de
l'information ŕ analyser,
2. traitement de l'information et création d'un fichier "signature", puis mise en mémoire de ce fichier de référence sur un support (disque dur, carte ŕ puce, code ŕ barres),
3. phase de vérification, l'on procčde ici comme pour la création du fichier "signature" de référence, puis l’on compare les deux fichiers pour déterminer leur taux de similitude et prendre la décision qui s'impose.
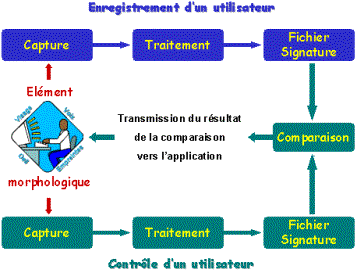
Figure 2 – [Biométrie online, page Techno.htm]
Les moyens biométriques
Voici quelques moyens actuellement ŕ l’étude :
ź les empreintes digitales,
ź la forme de la main,
ź le visage,
ź
la voix,
ź l’iris,
ź la rétine,
ź la signature dynamique,
ź la thermographie,
ź le code génétique (ADN).
Les performances biométriques
Il est impossible d'obtenir une coďncidence absolue (100% de similitude) entre le fichier "signature" créé lors de l'inscription et le fichier "signature" créé lors de la vérification. Les éléments d'origine (une image, un son...) utilisés pour les traitements informatiques ne pouvant jamais ętre reproduits ŕ l'identique.
Plutôt que de comparer les performances de ces systčmes, il faut surtout tenir compte de l'environnement de leur usage. Chaque technologie possédant des avantages et des inconvénients, acceptables ou inacceptables suivant les applications. Ces solutions ne sont pas concurrentes, elles n'offrent ni les męmes niveaux de sécurité ni les męmes facilités d'emploi.
En ce qui concerne « la voix », les avantages relevés sont les suivants :
ź c’est, ŕ ce jour, le seul moyen pour authentifier un interlocuteur via une liaison téléphonique,
ź par rapport aux autres technologies, il est plus facile de protéger le récepteur ; on pourra en effet aisément protéger un micro derričre une grille anti-vandalisme.
Mais « la voix », possčde aussi des inconvénients :
ź elles est sensible ŕ l’état physique de l’individu,
ź elle est sensible aux bruits ambiants,
ź il sera possible de frauder par un enregistrement,
ź les taux de faux rejets et fausses acceptations sont élevés.
1.5. L’authentification par « la voix »
Le domaine de recherche
concernant l’authentification vocale d’utilisateurs dans les systčmes
informatiques est l’Authentification Automatique du Locuteur (AAL). Ce domaine
pluridisciplinaire rassemble phonéticiens (production et perception de la
parole) et ingénieurs (traitement du signal, informatique, théorie de la décision)
[Besacier, 98].
L'identification de la voix est considérée par les utilisateurs comme une des formes les plus normales de la technologie biométrique, car elle n'est pas intrusive et n'exige aucun contact physique avec le récepteur du systčme.
Les systčmes d'identification de la voix se concentrent sur les seules caractéristiques de la voix qui sont uniques ŕ la configuration de la parole d'un individu. Ces configurations de la parole sont constituées par une combinaison de facteurs comportementaux et physiologiques.
Les sons se caractérisent par une fréquence, par une intensité et par une tonalité. Le traitement informatique tient compte des distorsions liées au matériel utilisé, et sait analyser un son de mauvaise qualité tel qu'une transmission téléphonique ou radiophonique.
Chaque personne possčde donc une voix propre que l'on peut analyser ŕ l’aide d’un micro.
La plupart des systčmes d'identification de la voix utilisent l'affichage d'un texte, des mots spécifiques doivent ętre lus puis répétés afin de vérifier que la personne ŕ authentifier est bien présente et qu'il ne s'agit pas d'un enregistrement.
Les imitateurs essayent habituellement de reproduire les caractéristiques vocales qui sont les plus évidentes au systčme auditif humain et ne recréent pas les caractéristiques moins accessibles. Il n'est donc pas possible d'imiter la voix d'une personne inscrite dans une base de données [Besacier, 98].
Toutefois, la fatigue, le stress ou un rhume peuvent provoquer des variations de la voix et générer des perturbations.
La fraude est également possible en enregistrant, ŕ son insu, la voix d'une personne autorisée.
La prochaine partie de notre étude vous présentera les différents niveaux d’authentification par la voix dans un certain nombre de contextes (application, identification, vérification, dépendance du texte) puis les critčres d’évaluation de leurs performances.
2. L’Authentification Automatique du Locuteur (AAL)
Il s’agit de reconnaître automatiquement l’identité d’une personne prononçant une ou plusieurs phrases, comme un auditeur humain identifie son interlocuteur au cours d’une conversation. Nous distinguerons :
1. les applications « sur site » : serrures vocales pour contrôle d’accčs, cabines bancaires en libre service,
2. les applications liées aux télécommunications : ces
applications concernent l’identification du locuteur ŕ travers le réseau téléphonique
pour accéder ŕ un service de transactions bancaires ŕ distance ou pour
interroger des bases de données en accčs privé,
3. les applications judiciaires : recherche de suspects,
orientations d’enquętes, preuves lors d’un jugement [Hollien, 90] [Künzel,
94].
La difficulté de la tâche d’authentification n’est pas la męme d’une application ŕ une autre. Dans le cas des applications « sur site », l’environnement de prononciation de la phrase ou du mot de passe est plus facilement contrôlé que dans le cas des applications via le réseau téléphonique (distorsions dues au canal, différences entre les combinés téléphoniques, bande passante limitée). Les applications judiciaires présentent quant ŕ elles des difficultés d’un autre ordre (locuteurs non-coopératifs, enregistrements de mauvaise qualité).
On distingue deux tâches différentes en Authentification Automatique du Locuteur (AAL) : l’identification du locuteur et la vérification du locuteur [Atal, 76] [Doddington, 85] [O’Shaughnessy, 86] [Furui, 94] [Eagles, 95].
L’identification du locuteur consiste ŕ reconnaître ce locuteur parmi une population (ou base) composée de N locuteurs connus. L’entrée du systčme est l’échantillon de parole d’un locuteur inconnu. La sortie du systčme correspond ŕ l’identité du locuteur de la base de référence qui est la plus "proche" du signal de parole inconnu. Dans cette tâche, on fait l’hypothčse que le signal de parole ŕ identifier est prononcé par l’un des locuteurs de la base de référence (identification en ensemble fermé).
La vérification du locuteur [Naik, 90] [Naik, 94b] [Rosenberg, 76] consiste ŕ déterminer si un locuteur est bien celui qu’il prétend ętre. Le systčme dispose en entrée d’un échantillon de parole et d’une identité proclamée. Une mesure de ressemblance est calculée entre l’échantillon et la référence du locuteur correspondant ŕ l’identité proclamée. Si cette mesure est en dessous d’un certain seuil, le systčme accepte le locuteur ; dans le cas contraire, le locuteur est considéré comme un imposteur et rejeté.
Il est ŕ noter que pour une identification en ensemble ouvert, la combinaison des deux tâches précédentes est nécessaire :
1. identification du locuteur le plus probable parmi les locuteurs de la base,
2. puis vérification que l’échantillon inconnu a bien été prononcé par le locuteur choisi dans l’étape d’identification.
2.2. Dépendance et Indépendance au texte
La distinction est faite entre les systčmes dépendants et indépendants du texte. En mode dépendant du texte, le texte prononcé par le locuteur (pour ętre reconnu du systčme) est le męme que celui qu’il a prononcé lors de l’apprentissage de sa voix. En mode indépendant du texte, le locuteur peut prononcer n’importe quelle phrase pour ętre reconnu.
Néanmoins, il existe plusieurs niveaux de dépendance au texte suivant les applications (listés selon le degré croissant de dépendance au texte) [Bimbot, 93] [Bimbot, 94] :
ź systčmes ŕ texte libre (ou free-text) : le locuteur prononce ce qu’il veut,
ź systčmes ŕ texte suggéré (ou text-prompted) : un texte, différent ŕ chaque session et pour chaque personne, est imposé au locuteur et affiché ŕ l’écran par la machine,
ź systčmes dépendants de traits phonétiques (ou speech event dependent) : certains traits phonétiques spécifiques sont imposés dans le texte que le locuteur doit prononcer,
ź systčmes dépendants du vocabulaire (ou vocabulary dependent) : le locuteur prononce une séquence de mots issus d’un vocabulaire limité (ex. : séquence de digits),
ź systčmes personnalisés dépendants du texte (ou user-specific text dependent) : chaque locuteur a son propre mot de passe.
Les systčmes dépendants du texte donnent généralement de meilleures performances d’authentification que les systčmes indépendants du texte car la variabilité due au contenu linguistique de la phrase prononcée est alors neutralisée.
2.3. Evaluation des performances en AAL
Les performances
d’identification du locuteur en ensemble fermé sont données par le taux
d’erreur d’identification (pourcentage des cas oů le systčme ne reconnaît
pas le bon locuteur).
Dans le cas d’un systčme
de vérification du locuteur, on distingue le taux de fausse acceptation (pourcentage
des cas oů le systčme accepte le locuteur alors que celui-ci n’est pas la
personne qu’il prétend ętre) ; et le taux de faux rejet
(situation oů le systčme
rejette le locuteur alors qu’il est vraiment la personne qu’il prétend ętre).
L’évaluation des performances d’un systčme d’AAL n’est cependant pas un problčme commun et on ne peut comparer deux systčmes ŕ partir de ces seuls taux d’erreur qui dépendent de multiples facteurs. Ainsi, les éléments suivants doivent également ętre pris en compte :
ź qualité de la parole : enregistrements en studio ou via le canal téléphonique ; environnement calme ou bruyant ; type de réseau téléphonique,
ź quantité de parole : durée de parole pour l’apprentissage des références de chaque locuteur ; durée de parole des sessions de test,
ź variabilité intra-locuteur : la voix d’un locuteur dépend de son état physique et émotionnel ; de plus, le comportement d’un locuteur se modifie lorsque celui-ci s’habitue ŕ un systčme,
ź population de la base de locuteurs : en identification du locuteur, la taille de la population a une influence directe sur les performances ; la qualité de la population (proportion hommes/femmes, bonne répartition géographique des locuteurs parlant une męme langue) est également un facteur ŕ intégrer,
ź intention des locuteurs : la distinction est faite entre les locuteurs coopératifs (qui veulent ętre reconnus par le systčme) et les locuteurs non-coopératifs qui modifient leur voix pour ne pas ętre reconnus (cas de certaines applications judiciaires par exemple). Enfin, certains locuteurs imitent la voix d’une autre personne pour ętre reconnus ŕ sa place : ce sont des imposteurs. A ce propos, lors de l’évaluation d’un systčme, les imposteurs sont en général d’autres locuteurs de la base de référence ce qui n’est pas trčs réaliste. En effet, en pratique, un imposteur réel qui tentera d’imiter la voix du locuteur pour lequel il voudra ętre reconnu, n’existera pas forcément dans la base de référence.
Les problčmes d’évaluation sont largement discutés dans le cadre du projet européen EAGLES [Chollet, 97] qui a pour but d’uniformiser les procédures d’évaluation. Des campagnes d’évaluation en AAL ont également été lancées (campagnes NIST (National Institute of Standards and Technology) ) pour comparer les performances des systčmes sur une męme base de données ("bench-mark programmes") et dans des conditions identiques pour tous. On trouvera aussi un bon exemple sur le problčme de l’évaluation des performances dans [Oglesby, 95].
Dans cette section,
sont présentés la structure générale et les différents modules d’un systčme
d’AAL. Une revue critique des méthodes existantes est ensuite proposée en
soulignant les atouts et défauts respectifs de chaque méthode. A ce propos, il
est ŕ noter que le taux d’erreur d’identification (ou les taux
d’acceptation / faux rejet) d’un systčme d’AAL n’est pas le seul critčre
de sa qualité. Sont ŕ ajouter :
ź la rapidité de l’apprentissage des modčles et de la phase d’authentification,
ź la quantité de données nécessaire pour l’apprentissage des modčles de locuteurs,
ź la modularité, c’est-ŕ-dire la possibilité d’ajouter ou de supprimer un locuteur de la base sans modifier complčtement l’architecture du systčme [Artičres, 95],
ź la robustesse aux variations intra-locuteurs ou aux conditions d’enregistrement.
3.1. Structure d’un systčme d’AAL
La tâche d’authentification automatique du locuteur peut se subdiviser en trois étapes :
ź la paramétrisation,
ź la classification,
ź la décision.
Un premier module de traitement du signal réalise l’analyse acoustique du signal de parole. A l’issue de cette étape, le signal est représenté par des vecteurs de coefficients, ce qui permet de réduire l’information en quantité et en redondance. Ces vecteurs sont éventuellement représentés par un modčle mathématique ; on parle alors de méthodes paramétriques. Dans la phase de classification, les vecteurs du signal de test (ou leur modčle) sont comparés aux vecteurs des locuteurs de référence (ou ŕ leurs modčles). La phase de décision désigne le locuteur finalement reconnu.
La structure d’un systčme d’identification du locuteur en ensemble fermé est représentée sur la figure 3.
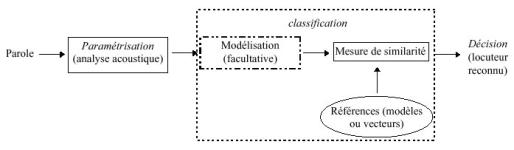
Figure 3 - Schéma modulaire d’un systčme d’identification du
locuteur en ensemble fermé
[Besacier, 98, page 9]
Les différents systčmes d’AAL existants se distinguent, d’une part suivant les paramčtres qu’ils utilisent, et d’autre part suivant les différents classificateurs qui prennent la décision finale.
Dans son article sur le
choix de paramčtres efficients pour l’authentification du locuteur, [Wolf,
72] décrit les attributs nécessaires des « bons paramčtres » pour
l’AAL. Idéalement, les paramčtres (ou traits acoustiques) doivent :
ź ętre fréquents,
ź ętre facilement mesurables,
ź ne pas ętre trop sensibles ŕ la variabilité intra-locuteur,
ź ne pas ętre affectés par le bruit ambiant ou les variations dues au canal de transmission,
ź ętre robustes face aux imitateurs.
En pratique, il est trčs difficile de réunir tous ces attributs en męme temps. La sélection de traits acoustiques pertinents pour l’AAL est donc un sujet largement traité : sélection de paramčtres séparant les locuteurs en terme de F-ratio (ou ses variantes) [Sambur, 75] [Bonastre, 92] ; sélection par programmation dynamique [Cheung, 78] ; sélection suivant les taux d’identification [Atal, 74]. Finalement, il ressort que les seuls types de paramčtres vraiment pertinents et utilisables efficacement sont les paramčtres de l’analyse spectrale et éventuellement les paramčtres prosodiques. Nous pouvons noter qu’ils sont respectivement corrélés ŕ la forme du conduit vocal et ŕ la source de l’appareil de production de la parole.
3.2.1. Paramčtres de l’analyse spectrale
Les principaux paramčtres de l’analyse spectrale utilisés en AAL sont les coefficients de prédiction linéaire et leurs différentes transformations (LPC (Linear Predictive Coefficients), LPCC (Linear Predictive Cepstral Coefficients), ...), ainsi que les coefficients issus de l’analyse en banc de filtres et leurs différentes transformations (coefficients banc de filtres, MFCC (Mel Frequency Cepstral Coefficients), ...).
Pour les coefficients de prédiction linéaire, on se référera par exemple aux thčses de [Grenier, 77] et [Homayounpour, 95]. Les articles suivants proposent quand ŕ eux une bonne synthčse sur le choix de paramčtres spectraux : [Reynolds, 94a] [Homayounpour, 94] [Ong, 94] [Charlet, 97]. Sans oublier l’utilisation des versions numériques : la TDF (Transformée Discrčte de Fourier), un algorithme de calcul rapide : FFT (Fast Fourier Transform). Toutefois, la TDF ne peut opérer sur des séquences trop courtes de signal [Haton, 91].
Le terme "paramčtres prosodiques" réunit l’énergie, la durée [Van den Heuvel, 94] et la fréquence fondamentale (ou pitch) [Atal, 72]. Ces paramčtres s’avčrent cependant fragiles en pratique et ne permettent pas, ŕ eux seuls, de discriminer les locuteurs. En conséquence, ils sont souvent associés aux paramčtres de l’analyse spectrale (surtout l’énergie). C’est aussi le cas pour la durée dans [Forsyth, 93] et pour la fréquence fondamentale dans [Matsui, 90] et [Dubreucq, 94].
3.2.3. Paramčtres exploitant la dynamique du signal de parole
La prise en compte d’une information de type dynamique peut ętre un facteur d’amélioration des performances d’identification du locuteur.
3.2.4.
Nouvelles paramétrisations
Aujourd’hui, les paramčtres utilisés sont pratiquement les męmes pour la plupart des systčmes d’AAL. Il existe cependant quelques exceptions comme [Thevenaz, 95] et [Hayakawa, 97] qui proposent d’utiliser le résidu de l’analyse par prédiction linéaire, combiné avec les coefficients LPC. [Wenndt, 97] utilise des paramčtres issus d’un bi-spectre (statistiques d’ordre supérieur), plus robustes aux dégradations en milieu bruité. Enfin, AEGIR SYSTEMS qui a participé ŕ la campagne d’évaluation NIST 97 [Nist, 97], utilise des coefficients issus d’une transformée en paquets d’ondelettes. La transformée en ondelettes ainsi que les autres transformées permettant une analyse multi-résolution du signal [Cohen, 95] sont trčs peu utilisées en traitement de la parole, malgré leur présence dans de nombreux autres domaines. On trouvera cependant quelques références sur le sujet dans [Navarro-Mesa, 92] [Wassner, 96] et [Bernstein, 97].
Cette étape consiste ŕ comparer les vecteurs du signal du
locuteur testé aux vecteurs des locuteurs de référence de la base de données.
Il existe différentes techniques de
classification utilisées lors de l’identification du locuteur indépendante
du texte ; quelques-unes vous sont présentées ci-aprčs :
ź spectres moyens :
[Pruzansky, 63] fut une
des premičres ŕ utiliser les paramčtres du spectre moyen ŕ long terme pour
l’AAL. Elle obtint un taux d’identification de 90 % sur une base de dix
personnes.
ź méthodes statistiques du second ordre :
Des mesures entre matrices de covariance ont été proposées par [Grenier, 77] et [Gish, 90]. Elles sont faciles ŕ implémenter et donnent de trčs bons résultats [Gish, 94] [Bimbot, 95] avec des durées de test relativement courtes (moins de 3s).
ź Modčles Auto Régressif Vectoriels (MARV) :
Ces modčles ont pour vocation de prendre en compte la dynamique du signal de parole. On trouvera notamment l’application des MARV pour l’AAL dans [Montacié, 92a] et [Montacié, 92b]. Une étude sur le choix de l’ordre des modčles (i.e. le nombre de trames utilisées pour la prédiction) est proposée dans [Griffin, 94]. Cependant, un ordre élevé des modčles engendre une complexité de calcul difficile ŕ contrôler.
3.3.2. Méthodes connexionnistes
L’utilisation des réseaux de neurones en AAL est relativement récente [Oglesby, 90] [Bennani, 90]. On trouvera cependant un bon exemple sur le sujet dans [Bennani, 95].
ź réseaux de neurones et discrimination :
Les réseaux
multicouches (MLP (Multi Layer Perceptron) ) utilisés au départ ont rapidement
présenté des problčmes lors de l’apprentissage qui devient long et complexe
quand le nombre de locuteurs est grand [Rudasi, 91]. Pour éviter ce problčme,
la tâche de classification est divisée en plusieurs sous-tâches de complexité
moindre pour chaque paire de locuteurs. Un apprentissage plus rapide peut également
ętre obtenu en remplaçant les réseaux multicouches par des réseaux RBF
(Radial Basis Function) [Oglesby, 91] [Frederickson, 94] [Furlanello, 95]. Les réseaux
TDNN (Time Delay Neural Networks) permettent quand ŕ eux de prendre en compte
l’information dynamique en réalisant la classification sur des segments de
plusieurs trames concaténées [Bennani, 92]. Enfin, l’approche LVQ (Learning
Vector Quantization) [Driancourt, 92] [Bennani, 95] est une méthode de type
quantification vectorielle avec apprentissage discriminant des vecteurs de référence
ŕ l’aide d’un réseau de neurones.
ź réseaux de neurones et modélisation :
Un défaut majeur des réseaux de neurones en classification est le problčme de modularité [Artičres, 95]. En effet, dans le cas d’un apprentissage discriminant, les modčles de tous les locuteurs doivent ętre re-appris quand une nouvelle personne est ajoutée dans la base. Les modčles prédictifs permettent de modéliser un locuteur indépendamment de tous les autres.
3.3.3. Modélisation multi-classes
ź approches par segmentation explicite :
Dans cette approche, le signal de parole segmenté est utilisé pour entraîner des modčles de classes acoustiques dépendants du locuteur. Dans [Bonastre, 94a] et [Bonastre, 94b], un score d’authentification est calculé pour chaque phončme du signal de parole préalablement segmenté, puis ces scores sont combinés afin de prendre une décision finale. [Olsen, 97] propose un systčme de vérification du locuteur en deux phases : une premičre phase de Décodage Acoustico-Phonétique (DAP) utilisant des HMM (Hidden Markov Model), puis une phase d’authentification du locuteur basé sur des réseaux RBF dépendants des phončmes. On trouve également ce type d’approche dans [Savic, 90] et [Matsui, 91] qui obtiennent de bonnes performances avec des durées de test courtes. Il est intéressant de noter qu’avec ces systčmes, les taux d’erreur sont pratiquement les męmes en mode dépendant ou en mode indépendant du texte.
ź approches par segmentation implicite :
Une premičre possibilité, introduite par [Soong, 85] consiste ŕ regrouper les vecteurs acoustiques en classes. La méthode de quantification vectorielle (VQ (Vector Quantization) ) [Soong, 86] est la plus souvent utilisée. L’emploi de la quantification vectorielle en AAL est notamment proposé dans [Matsui, 91] [Matsui, 92] [He, 97]. Une prise en compte de la nature séquentielle des événements phonétiques, associée ŕ la quantification vectorielle, a également été proposée par [Higgins, 86].
La seconde possibilité consiste ŕ utiliser des modčles probabilistes. [Poritz, 82] propose un HMM ŕ 5 états pour classer les vecteurs de paramčtres du signal d’un locuteur en 5 catégories correspondant chacune ŕ un état du HMM. [Tishby, 91] propose une extension de ces modčles en décrivant un état comme une combinaison linéaire (mixture) de gaussiennes. Cependant, une expérience de [Matsui, 92] comparant les approches VQ aux HMM en mode indépendant du texte n’a pas montré une différence de performance significative entre les deux techniques. Ces modčles ŕ base de mixtures de gaussiennes (GMM (Gaussian Mixture Model) ) sont désormais largement utilisés en AAL [Reynolds, 94b] [Gish, 94] [Reynolds, 95] [Markov, 96] [Lamel, 97] [Schmidt, 97] et fournissent les meilleurs résultats actuels. Les GMM semblent également ętre un peu plus robustes quand les environnements d’apprentissage et de tests diffčrent [Van Vuuren, 96].
3.3.4. Un point sur les performances actuelles
L’institut américain NIST organise chaque année une campagne d’évaluation des systčmes d’identification du locuteur. En 1997, la campagne portait sur la tâche de vérification du locuteur indépendante du texte [Nist, 97]. Neuf compétiteurs ont participé ŕ cette campagne : Aegir, BBN, Dragon, ENST, IDIAP, ITT, MIT, OGI et SRI. Le classement final s’est fait sur :
ź un apprentissage sur environ 1 minute de parole correspondant ŕ un mélange de 2 conversations enregistrées sur 2 combinés téléphoniques différents,
ź une mesure de performances réalisée ŕ partir d’un segment de test de 30 secondes environ.
Les performances sont évaluées séparément pour les portions de test utilisant un combiné téléphonique déjŕ présent dans la base d’apprentissage et pour les portions de test utilisant un combiné inconnu de la base d’apprentissage. Le score, qui permet le classement final des systčmes, est donné par une fonction de coűt égale ŕ la somme pondérée des probabilités de faux rejet et de fausse acceptation. Sur cette évaluation, huit laboratoires ont été classés [Besacier, 98].
Le classement final, ainsi que les méthodes utilisées par les laboratoires sont rassemblés dans le tableau 1.
Tableau 1 - Classement final de la campagne d’évaluation NIST 97. – [Besacier, 98, page 18]
|
Laboratoire |
Dragon 2 |
MIT1 |
BBN1 |
Dragon 1 |
OGI |
ITT |
IDIAP - ENST |
SRI |
|
Classement |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
|
Méthode |
GMM |
GMM |
GMM |
LVCSR |
GMM |
VQ |
Hybrid HMM / MLP |
GMM / LVCSR |
Il en ressort que la méthode de classification GMM est la plus performante.
La phase de décision désigne le locuteur finalement reconnu. Le procédé de cette phase dépendra fortement de la phase de classification choisie. Dans cette phase de décision, le locuteur sera accepté, reconnu ou rejeté suivant un seuil de décision, car on ne pourra jamais avoir 100% de similitude entre le signal du locuteur testé et le signal des locuteurs de la base de référence.
4. Analyse de produits commercialisés et de prototypes de recherche
Une certain nombre de sociétés ainsi que leurs produits vous sont présentés ci-aprčs. Vous trouverez une brčve description de chaque société, une énumération et description de leurs produits d’AAL, les caractéristiques techniques de chaque produit, ainsi que le marché et les applications visés.
7 sociétés/produits sont présentés ci-aprčs :

E-mail :
info@configate.com
Web :
http://www.configate.com
Téléphone :
+972-8-9316701
Fax :
+972-8-9316702
Adresse postale :
Configate, Unit 231 2 Professor Bergman St., Rabin Science Park, Rehovot
76705, Israel
CONFIGATE est
une compagnie spécialisées en biométrie et plus précisément dans la vérification
de la voix sous forme d’authentification pour l’accčs ŕ distance sur
Internet et la téléphonie. Fondée en 1999, la philosophie de cette société
est d’identifier et d’évaluer les caractéristiques naissantes de la vérification
de la voix [Configate].
Produit :
CONFIGATE propose un produit appelé « Verimote ». Son utilisation se décompose en 2 phases :
1. l’inscription : l’utilisateur doit exprimer oralement un mot de passe composé de trois mots de son choix. Le profil de la voix de l’utilisateur, appelé un « voiceprint », est enregistré dans une base de données,
2. la vérification : l’utilisateur est amené ŕ réitérer la prononciation de son mot de passe. La vérification se fait immédiatement et donne droit ou non ŕ l’accčs.
Marché et Application :
Entre autres :
ź les services financiers,
ź le commerce électronique,
ź la formation en ligne,
ź le télétravail,
ź la sécurité de l’information,
ź le contrôle d’accčs physique.
Caractéristiques Techniques :
ź longueur du mot de passe : 2 ŕ 4 secondes,
ź temps d’inscription : environ 30 secondes,
ź taille d’un « voiceprint » : approximativement 10 Ko comprimé,
ź temps de vérification : environ 2 secondes (dépend de l’encombrement du réseau),
ź systčme d’exploitation du serveur : Windows NT, Sun Solaris,
ź systčme d’exploitation du client : Windows 95/98, Windows NT/2000, Macintosh.
4.2. BUYTEL Ltd et ITT INDUSTRIES

|
E-mail : speakerkey@buytel.com
-
voicekey@buytel.com |
E-mail : speakerkey@itt.com
-
voicekey@itt.com |
La société ITT est une compagnie de fabrication industrielle. Elle est le principal fournisseur des systčmes militaires sophistiqués de la défense ainsi que des d’éléments électroniques pour les téléphones cellulaires et cartes PC pour les ordinateurs portables. L’associé d’ITT pour les services de « SpeakerKey » est BUYTEL. BUYTEL est l’un des principaux fournisseurs de services téléphoniques.
Les services de « SpeakerKey » fournissent de nouvelles normes d’exécution et de convenance pour l’accčs et l’identification d’utilisateurs [Buytel], [ITT and Buytel].
Produits :
ź PhoneKey : authentification vocale via le téléphone,
ź NetKey : via un réseau local,
ź WebKey : via Internet.
Marché et Application :
Entre autres :
ź commerce électronique,
ź services financiers en ligne,
ź téléphone,
ź formation en ligne,
ź assurance chômage en ligne,
ź avantages d’assistance sociale en ligne.
Correspondance
A la suite d’échange d’e-mails (annexes 1 et 2a) avec ces deux sociétés, j’ai constaté qu’il n’était pas possible de connaître précisément les méthodes utilisées pour l’élaboration de leur produit d’AAL. La société ITT m’a tout de męme indiqué qu’elle utilisait la méthode HMM ainsi que d’autres méthodes non divulguées. En effet, ces informations sont de propriété industrielle donc strictement confidentielles.

E-mail
Web : http://www.motorola.com
Téléphone : +602-441-5009
MOTOROLA est l’un des principaux fournisseurs mondiaux des transmissions sans fil, des semi-conducteurs ainsi que des systčmes, des composants et des services électroniques avancés.
Produit :
Le kittm de logiciel de vérification du locuteur « CipherVox » est le dernier né de la famille de produits de sécurité de l’information de MOTOROLA.
Marché et Application :
C’est un systčme que les développeurs pourront insérer dans leurs programmes. « CipherVox » se pręte ŕ beaucoup de plate-forme et ŕ une variété d’applications.
Caractéristiques Techniques :
ź temps d’inscription : environ 1 minute,
ź taille d’un « voiceprint » : trčs petit,
ź temps de vérification : moins d’1 seconde.
E-mail
Web
Fax : (613) 745-7473
Adresse Postale
1900 City Park
Drive
Suite 204
Gloucester
Ontario K1J 1A3
Canada
Fournisseur international de produits de sécurité, il développe également des technologies d’identité biométrique de la voix [OTG].
Produits :
ź « Help Yourself » est une solution prenant en charge une partie du travail du service de maintenance informatique dans une société. La prise en charge porte sur la maintenance des mots de passes, codes PIN (Personal Identification Number), identifiant de profils, etc. oubliés par les utilisateurs. Par exemple, l’utilisateur en panne pourra obtenir son mot de passe oublié grâce ŕ sa propre voix en se reliant au systčme « Help Yourself »,
ź « SecurPBX » est un produit de téléphonie qui fournit la sécurité d’accčs ŕ distance aux sociétés telle que l’audio-messagerie, les données, etc..
Marché et Application :
ź toute entreprise ayant un service d’aide pour le dépannage des mots de passe oubliés ou autres codes pour les systčmes informatiques, pourra réduire les coűts de cette maintenance en utilisant « Help Yourself »,
ź vérification du locuteur ŕ distance ŕ travers le réseau téléphonique.
Caractéristiques Techniques :
ź configuration : PC, 400 Mhz, 5Go de disque dur, 64 Mo de RAM,
ź systčme d’exploitation : Windows NT,
ź taille d’un « voiceprint » : 40 Ko.

E-mail :
Pat.Flannery@T-NETIX.com
Web :
http://www.T-NETIX.com
Téléphone :
(303) 705-5525
Fax :
(303) 790-9540
Adresse postale :
T-NETIX, Inc., 67 Inverness Drive East, Englewood, Colorado 80112, USA
T-NETIX fournit des services de sécurité pour les télécommunications. Elle développe des technologies de pointe d’authentification du locuteur appelées « SpeakEZ » [T-Netix].
Produits :
ź VoicEntry I : remplace votre mot de passe écrit de votre économiseur d’écran de Windows 95/NT, par un mot de passe vocal, en utilisant la technologie d’AAL dépendante du texte,
ź VoicEntry II : remplace tous les mots de passe rencontrés sous Windows 95/98/NT (ouverture de session, accčs au réseau, économiseur d’écran, etc.), par un mot de passe vocal,
ź VeriNet WEB : spécifique aux serveurs Web, garantit une vérification de l’utilisateur par contrôle vocal,
ź Software Development Kit : kit permettant d’intégrer la technologie d’AAL dans les programmes développés par l’entreprise.
Caractéristiques Techniques :
VoicEntry I et VoicEntry II :
ź PC 150 Mhz,
ź carte son,
ź microphone,
ź 5 Mo d’espace disponible sur le disque dur,
ź 24 Mo de RAM pour Windows NT et 16 Mo pour Windows 95/98.
VeriNet
WEB :
ź IIS (Internet Information Server) 4,
ź Internet Explorer 4.x ou Navigator 4.x au minimum.
SoftWare
Development Kit :
ź taille du code pour l’inscription : 90 Ko,
ź taille du code pour la vérification : 150 Ko,
ź longueur d’un mot de passe : 1 ŕ 2 secondes,
ź durée d’inscription : 30 secondes,
ź durée d’apprentissage : 5 secondes,
ź taille du « VoicePrint » : de 16 ŕ 25 Ko,
ź durée de vérification : 0,2 secondes,
ź configuration : Pentium 100 Mhz,
ź RAM : 32 Mo,
ź disque dur : 40 Mo,
ź
systčme
d’exploitation : Windows NT 3.51, 4.0, Windows 95/98.
Partenaires :
ź
BioNetrix ( http://www.bionetrix.com
),
ź Envox ( http://www.envox.com ),
ź
IBM ( http://www.ibm.com
),
ź
Lucent Technologies (
http://www.lucent.com ),
ź
Nortel Networks
( http://www.nortelnetworks.com ),
ź
OTG ( http://www.securpbx.com
),
ź
Periphonics ( http://www.peri.com
),
ź
Sentry Systems
( http://www.sentry-systems.com ),
ź
Stratus ( http://www.stratus.com
),
ź
Visionics
Corporation ( http://www.faceit.com ).
Correspondance
Aprčs un échange d’e-mails (annexes 1 et 2c), T-NETIX m’a
fourni un fichier joint
illustré de figures décrivant globalement les méthodes utilisées (figure
4.a),
la robustesse, les phases d’enregistrement (figure 4.b) et de vérification.
Ce fichier qui est ŕ votre disposition sur mon site Internet ŕ l’adresse
http://www.chez.com/gipp/oraux/aal/SpeakEZ_Voice_Print_Overview.doc (255 Ko)
m’a apporté un certain nombre d’informations que vous trouverez ci-aprčs :

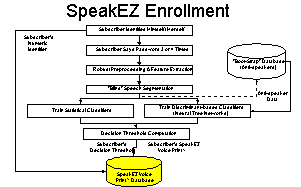
Figure 4.a
Figure 4.b
SpeakEZ utilise une combinaison de deux classificateurs :
1. l’un basé sur la discrimination (Discriminant-based),
2. l’autre basé sur les statistiques (Statistical-based).
Un réseau de neurone NTN (Neural Tree Network) est un arbre de neurones composé de nśuds (neurones) discriminants. Pendant le procédé de vérification dans le classificateur NTN, chaque nśud doit décider si les caractéristiques acoustiques sont identiques ŕ ceux de la personne proclamée ou identique ŕ ceux des autres personnes enregistrées dans la base de données. La technologie NTN permet une prise de décision rapide (plus rapide que les autres technologies aux dires d’T-NETIX). Des décisions sont prises ŕ chaque nśud de l’arbre et une conclusion est faite aprčs avoir parcouru 5 ou 6 branches de l’arbre.
Ce produit était initialement développé pour l’utilisation lors de combats (guerres) c’est-ŕ-dire dans des conditions d’enregistrement difficile (environnement de bruit, de chaos et des canaux de transmission faibles).

E-mail :
info@verivoice.com
Web :
http://www.verivoice.com
Téléphone :
(609) 452-9220
Adresse postale : VeriVoice,
Inc., 5 Vaughn Dr, Princeton, NJ 08540
Fondée en 1995, « VeriVoice » est une société spécialisée dans les solutions biométriques de sécurité pour l’accčs aux systčmes informatiques et aux réseaux ŕ distance. La compagnie fournit un moteur de vérification qui peut ętre intégré dans les applications.
Produit :
ź VeriVoice.
Correspondance
A la suite d’échange d’e-mails (annexes 1 et 2c), j’ai pu obtenir une version bęta d’un économiseur d’écran. La seule information qui m’ai été donnée est que les méthodes mentionnées dans mon e-mail (annexe 1), ŕ savoir HMM, FFT, réseau de neurones, ont été utilisées pour la conception de leur produit.


E-mail :
jjk@dpt-info.u-strasbg.fr
Web :
http://lsiit.u-strasbg.fr/
Téléphone :
03 88 65 55 00
Fax :
03 88 65 55 01
Adresse postale : LSIIT
(Laboratoire des Sciences de l’Image, de l’Information et de la Télédétection),
Pôle API,
Boulevard Sébastien Brant, 67400 ILLKIRCH GRAFFENSTADEN CEDEX
Le LSIIT (Laboratoire des Sciences de l’Image, de l’Information
et de la Télédétection) est une unité mixte de recherche de l’ULP
(Université Louis Pasteur) et du CNRS (Centre National de la Recherche
Scientifique). C’est un laboratoire interdisciplinaire fédéré par
l’imagerie. Les grandes disciplines qui y sont représentées sont l’Informatique,
le Traitement du signal, l’Automatique, la Télédétection.
Produit :
ź un projet d’authentification par le visage et par la voix est en cours de réalisation.
Correspondance
Ayant la possibilité de recueillir directement des informations auprčs du LSIIT, j’ai appris que ce projet, dans sa partie concernant l’authentification par la voix, utilise la méthode de transformation de l’ondelette pour la phase d’analyse (ou paramétrisation) et un réseau de neurones dans la phase d’apprentissage (ou classificateur). C’est le seul projet oů les informations et les détails sur les méthodes utilisées m’ont été donnés ŕ profusion (par M. POH N. - stagiaire travaillant sur le projet – e-mail : normanpoh@i.am ). Ce projet associera deux méthodes biométriques. La premičre méthode est l’authentification par le visage, sous-projet réalisé en 1999 et présenté dans [Metzger, 99]. La deuxičme méthode étant l’authentification par la voix, sous-projet en cours de réalisation (2000) (figure 5).
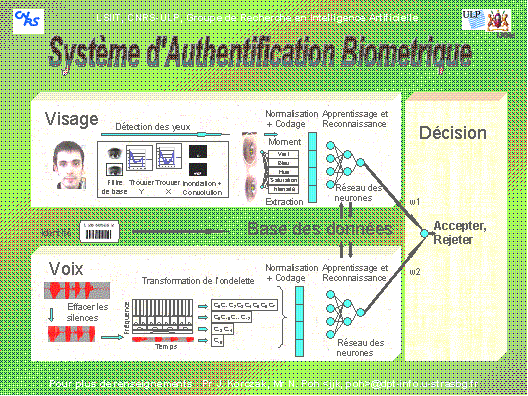
Figure 5
4.8. Tests des produits sélectionnés
SpeakerKey
de BUYTEL Ltd et ITT INDUSTRIES :
D’aprčs ces deux sociétés, une démonstration en ligne est proposée par téléphone au 00 1 (880) 775-7515, mais, malheureusement, aprčs plusieurs tentatives, nous avons constaté qu’aucun serveur ou service ne répondait ŕ l’appel.
Une autre démonstration est proposée directement via Internet ŕ l’adresse http://www.buytel.com/WebKey/index.asp ; elle simule un accčs en ligne ŕ un compte bancaire. Cette démonstration nous demande au préalable de télécharger et d’installer un « Plug-in » pour son bon fonctionnement.
Il nous est demandé, dans un premier temps, de saisir notre nom (figure 6.a) puis ensuite, de répéter oralement 12 paires de nombres aléatoires compris entre 40 et 99 ( « 97-46 » par exemple) (figures 6.b et 6.c). Le nom est alors associé au modčle d’apprentissage de la voix.
Pour accéder ultérieurement au compte bancaire simulé, il faudra saisir notre nom et répéter oralement 2 ŕ 4 paires de nombres aléatoires. Si le systčme affirme nous reconnaître, il nous présentera une page simulant notre compte bancaire (figure 6.d), le cas échéant, nous serons rejetés.
L’inscription effectuée restera stockée dans la base de données générale pour tout accčs ultérieur au compte bancaire. Pour toutes tentatives d’accčs par un autre ordinateur, il sera nécessaire de ré-installer le « plug-in » utile ŕ cette démonstration.
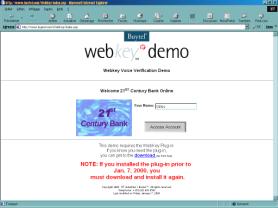
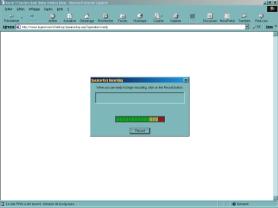
Figure 6.a
Figure 6.b
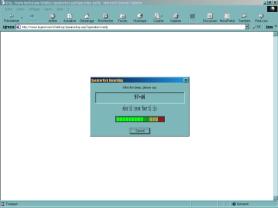
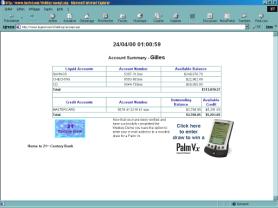
Figure 6.c
Figure 6.d
Mes propres essais ont été trčs concluants. En effet, avec l’aide de plusieurs locuteurs, nous avons tenté quelques essais d’intrusions, mais sans réussite. Il me semble que le fait que cette version de démonstration soit dépendante des traits phonétiques, la rende performante, męme en déformant volontairement sa voix.
Une autre version d’évaluation est également téléchargeable ŕ l’adresse http://www.voicekey.com/le/html/le_keygen1.html . Mais jusqu’ŕ présent ce téléchargement n’a jamais fonctionné !
VoicEntry de T-NETIX :
Une version de démonstration est téléchargeable ŕ l’adresse Internet http://www.t-netix.net/speakez/download.html ou directement ŕ http://www.t-netix.net/speakez/ve1.exe . Cette version s’installe sous Windows et propose un économiseur d’écran qui est désactivé par l’identification vocale du locuteur.
Aprčs son installation, le programme, peut ętre paramétré par le biais des « propriétés d’affichages » de Windows ; on y trouvera des réglages possible de sensibilité et de longueur de mot de passe (figure 7.a).
Une premičre étape consiste ŕ enregistrer sa voix, en prononçant 4 fois le męme mot de passe de son choix (figures 7.b et 7.c). Suit, une étape d’apprentissage de la voix enregistrée qui dure environ 8 secondes (sur un Pentium 350) (figure 7.d).
La troisičme étape est la vérification. Lorsque l’économiseur d’écran est en fonction, il suffit de déplacer la souris ou de presser une touche du clavier pour ętre invité ŕ prononcer son mot de passe (figure 7.e). Si le locuteur est identifié, l’économiseur cessera.
Une solution de secours est toutefois proposée aprčs plusieurs échec vocaux. En effet, un mot de passe écrit (paramétré dčs le début de l’apprentissage) est demandé pour désactiver l’économiseur d’écran.
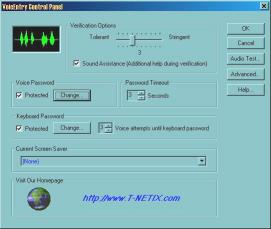

Figure 7.a
Figure 7.b
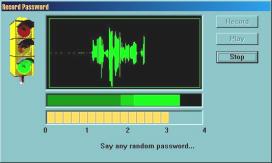
Figure 7.c
Figure 7.d
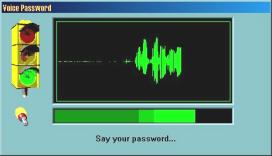
Figure 7.e
Aprčs avoir effectué de nombreux tests auprčs plusieurs locuteurs, il ressort les points suivants :
ź il s’agit d’une AAL dépendante du texte,
ź en déformant volontairement sa propre voix, l’identification semble quand męme fonctionner,
ź en tentant de réaliser quelques intrusions avec environ 5 locuteurs, l’un d’entre eux a tout de męme réussi ŕ tromper le programme !
VeriVoice :
Suite ŕ un échange d’e-mails, j’ai pu obtenir une version de démonstration similaire ŕ VoicEntry. Un économiseur d’écran pour Windows, mais dans ce cas précis, possibilité est donnée d’inscrire plusieurs « VoicePrint » en leur donnant des noms (figure 8.a). Dans cette version, la phase d’apprentissage (inscription) demande la prononciation de 16 séquences de 5 chiffres (exemple : 13052) (figures 8.b, 8.c, 8.d, 8.e et 8.f). Pour la vérification, il suffit de prononcer 1 seule séquence de 5 chiffres pour désactiver l’économiseur d’écran (figure 8.g).
Cette version de démonstration peut ętre téléchargée sur mon site ŕ l’adresse Internet suivante : http://www.chez.com/gipp/oraux/aal/VVSS20Apr00.exe (1 Mo).
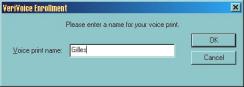
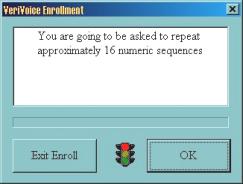
Figure 8.a
Figure 8.b
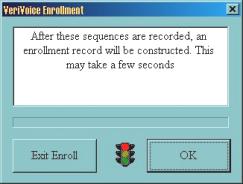
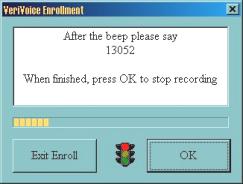
Figure 8.c
Figure 8.d
Figure 8.e
Figure 8.f
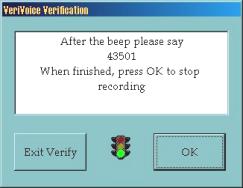
Figure 8.g
Aprčs avoir effectué de nombreux tests auprčs de plusieurs locuteurs, les points suivants ont été constatés :
ź il s’agit d’une AAL dépendante du vocabulaire,
ź ce systčme n’apparaît pas probant car une voix masculine a pu ętre remplacée par une voix féminine lors des essais,
ź les chiffres ŕ prononcer lors de l’apprentissage et lors de la vérification peuvent ętre énoncés dans n’importe quelle langue,
ź en déformant volontairement sa propre voix, l’identification semble quand męme fonctionner.
LSIIT, ULP-CNRS :
J’ai eu l’opportunité de voir fonctionner un projet d’authentification par le visage et par la voix réalisé ŕ LSIIT. Le programme résultant de ce projet (que j’ai d’ailleurs pu tester ŕ cette occasion) nous demande de nous enregistrer par « le visage » et par « la voix » (figure 9.a). Dans la premičre phase d’apprentissage, le programme prend un certain nombre de clichés ŕ l’aide d’une caméra et localise immédiatement la position des yeux du visage filmé (figure 9.b). Dans la deuxičme phase, nous sommes invités ŕ répéter oralement plusieurs fois un mot de passe d’une longueur maximum de 2 secondes (figure 9.c). En ce qui concerne la vérification, il est demandé de répéter ce męme mot de passe devant la caméra. Ce programme est donc dépendant du texte. Ses performances ne peuvent malheureusement pas encore ętre évaluées puisque le projet n’en est qu’ŕ ses débuts.
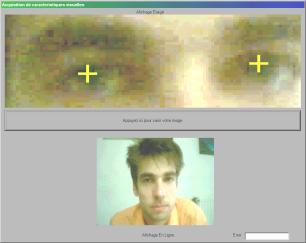
Figure 9.a
Figure 9.b
Figure 9.c
5. Problčmes et limites des systčmes actuels
Dans un tutorial sur les avancées récentes en authentification du locuteur, [Furui, 97a] propose 16 questions ouvertes concernant les interrogations et les problčmes restés sans solution ŕ ce jour. De nombreux problčmes sont liés ŕ la variabilité : variabilité due au locuteur et variabilité due aux conditions d’enregistrement.
5.1. Variabilité due au locuteur
Une dégradation croissante des performances a été observée au fur et ŕ mesure que le temps qui sépare la session d’apprentissage de la session de test augmente [Furui, 72] [Furui, 74] [Rosenberg, 76]. De plus, le comportement des locuteurs se modifie lorsque ceux-ci s’habituent au systčme. Les modčles des locuteurs doivent donc ętre réguličrement mis ŕ jour avec les nouvelles données d’exploitation du systčme [Setlur, 95]. Les altérations de la voix dues ŕ l’état physique (fatigue, rhume) ou émotionnel (stress) mettent aussi en échec l’efficacité des systčmes [Homayounpour, 94].
5.2. Variabilité due aux conditions d’enregistrement et de transmission
La parole téléphonique
est sujette ŕ des dégradations parmi lesquelles on peut citer la limitation de
la bande utile et les distorsions dues au combiné ou au canal de transmission
[Reynolds, 92].
Une diminution des
performances pour de la parole téléphonique est systématiquement observée
[Hunt, 83] [Gish, 85] [Gish, 86]. [Reynolds, 94b] observe une dégradation des
performances d’identification qui passent de 99.7 % sur TIMIT (Texas
Instruments Massachusetts Institute of Technology) ŕ 76.2 % sur NTIMIT (Network
TIMIT) pour 168 locuteurs. Plus récemment, [Van Vuuren, 96] a fait le point sur
les problčmes dus aux différences entre les environnements téléphoniques.
Ainsi, dans le cas oů les données d’apprentissage et les données de test ne
viennent pas du męme environnement téléphonique, la dégradation des
performances d’identification du locuteur est trčs importante. [Reynolds, 96]
a montré que la plus grande part de ces dégradations est due aux différences
de combinés téléphoniques entre l’apprentissage et le test. Une détection
préalable du combiné téléphonique semble donc nécessaire. Ce point précis
était d’ailleurs l’un des enjeux essentiels lors de la campagne d’évaluation
NIST 97.
Récemment, [Kuitert, 97] a étudié l’effet du codage de la parole utilisé dans le réseau téléphonique mobile GSM sur les performances de vérification du locuteur.
Peu d’articles traitent du problčme de la robustesse des systčmes confrontés ŕ de la parole enregistrée dans un environnement bruité. La robustesse au bruit ambiant est pourtant une condition nécessaire au succčs des systčmes d’AAL dans des applications en conditions réelles.
Enfin, une autre condition est la robustesse vis ŕ vis des imitateurs occasionnels ou professionnels [Homayounpour, 94]
6. Quelques solutions aux problčmes de robustesse
Nous avons vu dans la
section précédente que la plupart des problčmes rencontrés en AAL sont dus
ŕ une inégalité entre les conditions d’apprentissage et les conditions de
test : variabilité due au locuteur, au canal de transmission ou aux
conditions d’enregistrement.
Les méthodes traitant de la réduction des écarts dus aux variations du signal de parole peuvent ętre regroupées en deux niveaux [Furui, 97b] :
ź niveau des paramčtres,
ź niveau des modčles.
6.1. Paramétrisations robustes
Le problčme de la robustesse des paramčtres pour l’AAL a notamment été abordé par [Assaleh, 94] [Naik, 94a] et [Reynolds, 94a]. Les paramčtres peuvent également ętre retraités aprčs l’analyse acoustique : égalisation de canal [Furui, 81] [Wang, 93], filtrage RASTA (RelAtive SpecTraAl) [Hermansky, 94] [Hermansky, 97], masquage du bruit par addition d’un offset aux paramčtres spectraux [Openshaw, 94]. Le défaut de l’égalisation de canal est qu’elle supprime en męme temps une partie de l’information spécifique du locuteur [Furui, 97a].
6.2. Ré-estimation ou adaptation des modčles
Comme la voix des locuteurs évolue au cours du temps, il est nécessaire de mettre ŕ jour les modčles des locuteurs pour éviter leur vieillissement. Pour des raisons pratiques, les modčles doivent ętre mis ŕ jour en utilisant les données d’exploitation. On peut soit ré-estimer les modčles des locuteurs en utilisant les données d’apprentissage initiales et les nouvelles données d’exploitation, soit adapter le modčle initial du locuteur avec les données d’exploitation. Cette deuxičme alternative ne nécessite aucun stockage des données de sessions précédentes puisque l’adaptation se fait ‘en ligne’ [Matsui, 96].
L’adaptation des modčles est également nécessaire sur de la parole téléphonique pour prendre en compte les différentes conditions d’appel (combiné, canal, ...). Une premičre solution consiste ŕ créer le modčle d’un locuteur ŕ partir de différents environnements d’appel [Gauvain, 95]. [Heck, 97] propose quant ŕ lui d’entraîner différents modčles dépendants du combiné téléphonique pour normaliser le score d’un locuteur.
Récemment, de nouvelles techniques sont apparues en vue d’augmenter la robustesse des systčmes d’authentification : leur caractéristique commune est l’utilisation de plusieurs re-connaisseurs (travaillant en parallčle) qui sont re-combinés pour prendre une décision finale [Besacier, 98].
Nous avons pu constater que le domaine de la biométrie est une véritable alternative aux mots de passe qui permet de vérifier que l’utilisateur soit bien la personne qu’il prétend ętre. Cette technologie est en pleine croissance et l’authentification par la voix, ainsi que les autres moyens d’authentification, tendent ŕ s’associer ŕ court terme, aux technologies actuelles comme la carte ŕ puce, le badge, la clé, etc..
La fabrication des produits d’authentification est en pleine augmentation, dű en l’occurrence ŕ la nécessité croissante du besoin de sécurité de chacun (tant dans le domaine privé que dans le domaine professionnel).
Les méthodes actuelles utilisées pour la réalisation de l’apprentissage et de la vérification sont nombreuses et en pleine mutation. Elle sont toutefois la propriété des fabricants et centres de recherche qui travaillent souvent de façon autonome et sans aucune corrélation. Aussi, ne serait-il pas judicieux d’associer toutes les connaissances sur le sujet (quelque soit le pays et le domaine de recherche), afin de pouvoir obtenir des outils probants et fiables ?
Pour autant, le coűt prohibitif de ces technologies a longtemps freiné leur développement. Aujourd’hui, les entreprises entrevoient les économies qu’elles réaliseraient ŕ long terme en les utilisant (ex : temps perdu par les services informatiques pour retrouver les mots de passe oubliés ou perdus).
Notons que la société MICROSOFT se lance également dans la biométrie puisqu’elle a annoncé son intention d’offrir le support de technologie biométrique aux utilisateurs de Windows 2000 avant de l’incorporer pleinement ŕ la sécurité Windows ŕ l’avenir.
L’industrie biométrique représentera un milliard de dollars en 2000 et elle devrait connaître un boom fantastique dčs lors qu’elle aura converti le secteur privé (pour le moment les plus gros utilisateurs sont les prisons, les services de police, etc.) ; toutefois, il devrait se passer un peu de temps avant que ces technologies soient largement adoptées [Vnunet, 2000].
L’on a également pu constater que l’authentification par la voix est un moyen biométrique difficile ŕ réaliser. Elle semble fonctionner, mais les programmes de démonstration ont été testés avec des locuteurs dont le but premier n’était pas la fraude ! De plus, les produits testés dans ce présent rapport, étaient pour certains en cours de réalisation et pour d’autres des versions de démonstration. Aussi, pour une meilleure évaluation de ces produits, il serait ŕ l’évidence nécessaire d’attendre la version finale pour les tester au mieux.
Enfin, pour qu’un systčme d’authentification soit robuste et paré ŕ toute épreuve l’on peut penser qu’il serait préférable d’associer simultanément plusieurs méthodes d’authentification biométrique en combinant, par exemple, « la voix » et « les traits du visage », comme l’a d’ailleurs suggéré le LSIIT.
Toutefois, « la voix » reste ŕ ce jour le seul moyen d’authentification par téléphone…
Annexe 1 : E-mail envoyé aux adresses suivantes : sksupport@acdca.itt.com ; speakerkey@itt.com ; voicekey@itt.com ; voicekey@buytel.com ; info@configate.com ; info@otg.ca ; P14215@email.mot.com ; SDKSales@T-NETIX.com ; info@verivoice.com ; speakerkey@buytel.com ; Information@T-NETIX.com ; Ray.Reid@T-NETIX.com ; Ron.Beyner@T-NETIX.com ; UK_office@T-NETIX.com
|
De: Gilles <gipp@chez.com> Hello, |
Annexe 2a : Réponses de BUYTEL et ITT
|
De: Vance Harris <
Vance@buytel.com > |
|
De: Smead, Frank <
Frank.Smead@itt.com > |
Annexe 2b : Réponses de T-NETIX
|
De: Ray Reid <
Ray.Reid@T-Netix.Com > |
|
De: Bill Mistretta <
Bill.Mistretta@t-netix.com
> |
Annexe 2c : Réponse de VERIVOICE
|
De : Joseph A. Mannino <
jmannino@verivoice.com > |
|
AAL |
Authentification Automatique du Locuteur |
|
DAP |
Décodage Acoustico-Phonétique |
|
GMM |
Gaussian
Mixture Model |
|
HMM |
Hidden
Markov Model |
|
LPC |
Linear
Predictive Coefficients |
|
LPCC |
Linear
Predictive Cepstral Coefficients |
|
LVCSR |
Large
Vocabulary Continuous Speech Recognition |
|
LVQ |
Learning
Vector Quantization (Algorithm) |
|
MARV |
Modčle Auto Régressif Vectoriel |
|
MFCC |
Mel
Frequency Cepstral Coefficients |
|
MLP |
Multi Layer Perceptron |
|
NIST |
National
Institute of Standards and Technology |
|
NTIMIT |
(Telephone)
Network TIMIT |
|
NTN |
Neural
Tree Network |
|
PIN |
Personal Identification Number |
|
RASTA |
RelAtive
SpecTrAl (Methodology) |
|
RBF |
Radial
Basis Function |
|
TDNN |
Time
Delay Neural Network |
|
TIMIT |
Texas
Instruments Massachusetts Institute of Technology |
|
VQ |
Vector Quantization |
|
[Artičres, 95] |
Méthodes prédictives neuronales : applications ŕ
l’identification du locuteur. Thčse de l’Université de Paris XI
Orsay. 1995. |
|
[Assaleh,
94] |
ASSALEH
K.T. MAMMONE R.J.,
Robust cepstral features for speaker identification. In Proc. ICASSP 94, Adélaide, Australia, pp 129-132. 1994. |
|
[Atal,
72] |
ATAL
B.S.,
Automatic speaker recognition based on pitch contours. The Journal of the
Acoustical Society of America, n° 52, pp 1687-1697. 1972. |
|
[Atal,
74] |
ATAL
B.,
Effectiveness of linear prediction characteristics of speech wave of
automatic speaker identification and verification. JASA, vol. 55, pp 1304-1312. June 1974. |
|
[Atal,
76] |
ATAL
B.S.,
Automatic recognition of speakers from their voices. Proc.
IEEE, n° 64(4), pp 470-475. 1976. |
|
[Bennani, 90] |
BENNANI
Y., SOULIE F.F., GALLINARI P., A connectionist approach for automatic speaker identification. In
Proc. ICASSP
90, pp 265-268. April 1990. |
|
[Bennani,
92] |
BENNANI
Y.,
Speaker Identification through a modular connectionist architecture.
Evaluation on the TIMIT database. In Proceedings ICSLP 92, pp 607-610.
Banff (Canada). October 1992. |
|
[Bennani,
95] |
BENNANI
Y., GALLINARI P.,
Neural networks for discrimination and modelization of speakers. Speech
Communication, n° 17(1-2), pp 159-176. August 1995. |
|
[Bernstein,
97] |
BERNSTEIN
E., EVANS W.,
Wavelet based noise reduction for speech recognition, In ESCA-NATO
Workshop on Robust speech recognition for unknown communication channels. Pont-ŕ-Mousson,
France, pp 111-114. 17-18 Avril 1997. |
|
[Besacier, 98] |
BESACIER Laurent - PhD, PhD
Thesis. Adresse Internet : http://herakles.imag.fr/besacier/
, Un modčle
Parallčle pour la Reconnaissance Automatique du Locuteur. 1998. |
|
[Bimbot,
93] |
BIMBOT
F., PAOLONI A., CHOLLET G., Assessment Methodology for Speaker Identification and Verification
Systems. Technical report – Task 2500 – Report 19, SAM-A ESPRIT
Project 6819. 1993. |
|
[Bimbot,
94] |
BIMBOT
F., CHOLLET G., PAOLONI A., Assessment Methodology for Speaker Identification and Verification
Systems. In Workshop on Automatic Speaker Recognition and Verification, pp
75-82. Martigny
(Switzerland). April 1994. |
|
[Bimbot,
95] |
BIMBOT
F., MAGRIN-CHAGNOLLEAU T., MATHAN L., Second-order statistical methods for
text-independent speaker identification. Speech Communication, n°
17(1-2). August 1995. |
|
[Biométrie Online] |
BIOMETRIE ONLINE, Biométrie Online. Adresse Internet : http://biometrie.online.fr/ |
|
[Bonastre, 92] |
BONASTRE
J-F., MELONI H.,
A study of spectral variability for speaker characterisation. In
19čmes Journées d’Etudes sur la Parole, p 555. Juin 1992. |
|
[Bonastre, 94a] |
BONASTRE J-F., Stratégie
analytique orientée connaissances pour la caractérisation et
l’identification du locuteur. Thčse de Doctorat : Université
d’Avignon. 1994. |
|
[Bonastre, 94b] |
BONASTRE
J-F., MELONI H.,
Inter and Intra-speaker variability of French phonemes. Advantages of an
explicit knowledge based approach. In Workshop on Automatic Speaker
Recognition and Verification, pp 157-160. Martigny (Switzerland). April 1994. |
|
[Buytel] |
BUYTELTM,
Buytel. Adresse Internet : http://www.buytel.com/
|
|
[Charlet, 97] |
CHARLET
D., JOUVET D.,
Optimising feature set for speaker verification, In Proc. AVBPA
Spriner LNCS, Bigün, et al., Eds.. 1997. |
|
[Cheung,
78] |
CHEUNG
R.S., EISENSTEIN B.A.,
Feature selection via dynamic programming for text-independent speaker
identification. In IEEE Transactions on Speech and Audio Processing, vol
26, n° 5, pp 397-403. October 1978. |
|
[Chollet,
97] |
CHOLLET
G., BIMBOT F.,
Assessment of speaker verification systems. In Handbook of standards and
resources for spoken language systems. Mouton
de Gruyter. 1997. |
|
[Cohen,
95] |
COHEN
L.,
Time –Frequency Analysis, Prentice-Hall, Englewood Cliffs. 1995. |
|
[Configate] |
CONFIGATE, Configate.
Adresse Internet : http://www.configate.com/
|
|
[Doddington,
85] |
DODDINGTON
G.R.,
Speaker recognition. Identify people by their voices. Proceeding
IEEE, n° 73(11), pp 1651-1664. November 1985. |
|
[Driancourt,
92] |
DRIANCOURT
X., GALLINARI P.,
A speech recogniser optimally combining learning vector quantization,
dynamic programming and multi-layer perceptron. In Proc. ICASSP 92, San
Francisco, USA. 1992. |
|
[Dubreucq,
94] |
DUBREUCQ
V., VLOEBERGHS C.,
The use of the pitch to improve an HMM based speaker recognition method,
In Workshop on Automatic Speaker Recognition and Verification, Martigny (Switzerland),
pp 15-18. 1994. |
|
[Eagles,
95] |
Assessment
of speaker verification systems, In EAGLES Spoken Language Systems, Eagles
Document EAG-SLWG-Handbook Phase 2. February 1995. |
|
[Forsyth,
93] |
FORSYTH
M.E., JACK M.A.,
Duration modelling and multiple codebooks in semi-continuous HMM for
speaker verification. Eurospeech 93, Berlin, Germany, pp 319-322. 1993. |
|
[Frederickson,
94] |
FREDERICKSON
S.E., TARASSENKO L., Radial basis functions for speaker identification. In Workshop on
Automatic Speaker Recognition and Verification, pp 107-110. Martigny
(Switzerland). April 1994. |
|
[Furlanello,
95] |
FURLANELLO
C., GIULANI D., TRENTIN E., FALAVIGNA D., Applications of generalised radial basis functions
in speaker normalisation and identification. In Proceedings of IEEE
International Symposium on Circuit and Systems, pp 1704-1707. Seattle
(USA). April-May 1995. |
|
[Furui,
72] |
FURUI
S., ITAKURA F., SAITO S.,
Talker recognition by long time averaged speech spectrum. Elect. Commun,
Japan 55-A(10) pp 54-61. 1972. |
|
[Furui, 74] |
FURUI
S.,
An analysis of long term variation of feature parameters of speech and its
application to talker recognition, In Trans. IECE, 57-A, vol. 12, pp
880-887. 1974. |
|
[Furui, 81] |
FURUI
S.,
Cepstral analysis technique for automatic speaker verification. In
IEEE Trans. Acoust.
Speech Signal Processing, vol. 19, n° 2, pp 254-272. 1981. |
|
[Furui,
94] |
FURUI
S.,
An overview of speaker recognition technology. In Workshop on Automatic
Speaker Recognition and Verification, pp 1-9. Martigny (Switzerland). April 1994. |
|
[Furui,
97a] |
FURUI
S.,
Recent advances in speaker recognition. In Proc. AVBPA, Springer LNCS, Bigün, et al., Eds, pp
237-252. 1997. |
|
[Furui,
97b] |
FURUI
S.,
Recent advances in robust speech recognition. In ESCA-NATO Workshop on
Robust speech recognition for unknown communication channels. Pont-ŕ-Mousson,
France, pp 11-20. 17-18 Avril 1997. |
|
[Gauvain, 95] |
GAUVAIN
J-L., LAMEL L-F, PROUTS B., Experiments with speaker verification over the telephone. Eurospeech
95. Madrid, Spain, pp 651-654. 1995. |
|
[Gish,
86] |
GISH
H., KRASNER M., RUSSEL W., WOLF J., Methods and experiments for text-independent speaker recognition over
telephone channels. In Proc0 ICASSP 86, pp 865-868. 1986. |
|
[Gish,
90] |
GISH
H.,
Robust discrimination in automatic speaker identification. In
Proc. ICASSP 90, vol. 1, pp 289-292. 1990. |
|
[Gish,
94] |
GISH
H., SCHMIDT M.,
Text independent speaker identification. IEEE Signal Processing Magazine,
p 18. October 1994. |
|
[Grenier, 77] |
GRENIER Y., Identification
de locuteur et adaptation au locuteur d’un systčme de reconnaissance
phonétique. Thčse de Docteur Ingénieur : E.N.S.T. Paris. 1977. |
|
[Griffin,
94] |
GRIFFIN
C., MATSUI T., FURUI S.,
Distance measures for Text-independent speaker recognition based on MAR
Model. In Proceedings ICASSP. Adelaďde (Australia). 1994. |
|
[Grish,
85] |
GRISH
H., KARNOFSKY K., KRASNER M., ROUCOS S., SCHWARZ R., WOLF J.,
Investigation of text-independent speaker identification over telephone
channels. IN
Proc. ICASSP 85, pp 379-382. 1985. |
|
[Haton,
91] |
HATON J.P., PIERREL J.M., PERENNOU G.,
Reconnaissance automatique de la parole. 1991. |
|
[Hayakawa,
97] |
HAYAKAWA
S., TAKEDA K., ITAKURA F., Speaker Identification using harmonic structure of LP-residual
spectrum. In Proc. AVBPA, Springer LNCS, Bigün, et al., Eds, pp 253-260.
1997. |
|
[He,
97] |
HE
J., LIU L., PALM G.,
A new codebook training algorithm for VQ-based speaker recognition. In
Proc. ICASSP 97, Munich, Germany, pp 1091-1094. 1997. |
|
[Heck,
97] |
HECK
L-P., WEINTRAUB M.,
Handset dependent background models for robust text-independent speaker
recognition. In
Proc. ICASSP
97, Munich, Germany, pp 1071-1074. 1997. |
|
[Hermansky,
94] |
HERMANSKY
H., MORGAN N.,
RASTA Processing of Speech. IEEE Trans. On Speech and Audio Processing,
vol. 2, n° 4, pp 578-589. 1994. |
|
[Hermansky,
97] |
HERMANSKY
H.,
Should recognisers have ears ? In ESCA-NATO Workshop on Robust speech
recognition for unknown communication channels. Pont-ŕ-Mousson,
France. 17-18 Avril 1997. |
|
[Higgins,
86] |
HIGGINS
A.L., WOHLFORD R.E.,
A new method of text-independent speaker recognition. In Proc. ICASSP 86, pp 869-872. 1986. |
|
[Hollien,
90] |
HOLLIEN
H.,
The acoustics of crime. Applied Psycholinguistics and Communication
Disorders 1990. Plenum Press : New-York & London. p 370. 1990. |
|
[Homayounpour,
94] |
HOMAYOUNPOUR
M.M., CHOLLET G.,
A comparison of some relevant parametric representations for speaker
verification. In Workshop on Automatic Speaker Recognition and
Verification, pp 185-188. Martigny (Switzerland). April 1994. |
|
[Homayounpour, 95] |
HOMAYOUNPOUR M.M., Vérification
vocale d’identité : dépendante et indépendante du texte. Thčse
de Doctorat : Université de Paris Sud. 1995. |
|
[Hunt,
83] |
HUNT
M.,
Further experiments in text-independent speaker recognition over
communication channels. In Proc. ICASSP 83, pp 563-566. 1983. |
|
[ITT
and Buytel] |
ITT
INDUSTRIES et BUYTEL Ltd., SpeakerKey© Services. http://www.voicekey.com/
|
|
[Kuitert,
97] |
KUITERT
M., BOVES L.,
Speaker verification with GSM coded telephone speech. In Proc. Eurospeech
97, Rhodes, Greece. September 1997. |
|
[Künzel,
94] |
KUNZEL
H.J.,
Current approaches to forensic speaker recognition. In Workshop on
Automatic Speaker Recognition and Verification, pp 135-141. Martigny (Switzerland). April 1994. |
|
[Lamel,
97] |
LAMEL
L., GAUVAIN J-L.,
Speaker recognition with the switchboard corpus. In Proc. ICASSP 97,
Munich, Germany, pp 1067-1070. 1997. |
|
[Markov,
96] |
MARKOV
K., NAKAGAWA S.,
Frame level likelihood normalisation for text independent speaker
identification using gaussian mixture models. In Proc. ICSLP 96,
Philadelphia, USA, pp 1764-1767. 1996. |
|
[Matsui, 90] |
MATSUI
T., FURUI S.,
Text-independent speaker recognition using vocal tract and pitch
information. In Proceedings ICSLP 90, pp 137-140, 1990. |
|
[Matsui,
91] |
MATSUI
T., FURUI S.,
A text-independent recognition method robust against utterance variation. In
Proc. ICASSP 91, pp 377-380. 1991. |
|
[Matsui, 92] |
MATSUI
T., FURUI S.,
Comparison of text-independent speaker recognition methods using
VQ-distortion and discrete continuous HMMs. In Proc. ICASSP 92, San
Francisco, USA, pp 157-160. 1992. |
|
[Matsui, 96] |
MATSUI
T., FURUI S.,
Robust methods of updating model and a priori threshold in speaker
verification. In Proc. ICASSP 96,
Atlanta, EU, pp 97-100. 1996. |
|
[Metzger, 99] |
METZGER Serge, Mémoire :
Authentification de visages : Une approche neuronale. 1999. |
|
[Montacié, 92a] |
MONTACIE
C., LE FLOCH J.L.,
AR-Vector models for free-text speaker recognition. In Proceedings ICSLP
92, pp611-614. Banff (Canada). October 1992. |
|
[Montacié,
92b] |
MONTACIE
C., DELEGLISE P., BIMBOT F. CARATY M.J., Cinematic techniques for speech processing :
temporal decomposition linear prediction. In
Proc. ICASSP 92, vol.1, pp 153-156. San-Francisco, USA. 1992. |
|
[Naďk,
90] |
NAIK
J.M.,
Speaker verification : a tutorial. IEEE
Communications Magazine, pp 42-48. January 1990. |
|
[Naďk,
94a] |
NAIK
D., ASSALEH K., MAMMONE R.,
Robust speaker identification using pole filtering. In Workshop on
Automatic Speaker Recognition and Verification, pp 225-230. Martigny
(Switzerland). April 1994. |
|
[Naďk,
94b] |
NAIK
J.,
Speaker verification over the telephone network : databases,
algorithms and performance assessment. In Workshop on Automatic Speaker
Recognition and Verification, pp 31-38. Martigny (Switzerland). April 1994. |
|
[Navarro-Mesa,
92] |
NAVARRO-MESA
J.L.,
Optimum Window Length in Speech Signals – Time-Frequency Analysis, IEEE
Trans. On Signal Processing, Vol.40, n°2. February 1992. |
|
[Nist
97] |
MARTIN
A., PRZYBOCKI M.,
1997 speaker recognition evaluation NIST workshop, Maritime Institute
Linthicum, Maryland. 25-26 June 1997. |
|
[O’Shaughnessy,
86] |
O’SHAUGHNESSY
D.,
Speaker recognition. IEEE ASSP Magazine, pp4-17. October 1986. |
|
[Oglesby,
90] |
OGLESBY
J., MASON J.S.,
Optimisation of neural models for speaker identification. In
Proc. ICASSP 90, pp261-264. 1990. |
|
[Oglesby,
91] |
OGLESBY
J., MASON J.,
Radial basis function networks for speaker recognition. In Proc. ICASSP
91, 99 393-396. May 1991. |
|
[Oglesby,
95] |
OGLESBY
J.,
What’s in a number ? Moving beyond the equal error rate. Speech
Communication, n°17(1-2). August 1995. |
|
[Olsen
97] |
OLSEN
J.O.,
A two stage procedure for phone based speaker verification. In
Proc. AVBPA, Springer LNGS, Bigün, et al. Eds., pp 219-226. 1997. |
|
[Ong
94] |
ONG
S., MOODY M.P., SRIDHARAN S., Confidence Analysis for speaker identification : the
effectiveness of various features. In Workshop on Automatic Speaker
Recognition and Verification, pp 91-94. Martigny
(Switzerland). April 1994. |
|
[Openshaw,
94] |
OPENSHAW
J.P., MASON J.S.,
Optimal noise-masking of cepstral features for robust speaker
identification. In Workshop on Automatic Speaker Recognition and
Verification. Pp
231-234. Martigny (Switzerland). April 1994. |
|
[OTG] |
The
OTTAWA TELEPHONY GROUP Inc, OTG. Avril 2000. Adresse
Internet : http://www.otg.ca/ |
|
[Poritz,
82] |
PORITZ
A.B.,
Linear predictive HMMs and the speech signal. In
Proc. ICASSP 82, Paris, France, pp 1291-1294. 1982. |
|
[Pruzansky,
63] |
PRUZANSKY
S.,
Pattern matching procedure of automatic talker recognition. JASA,
vol.35, pp 354-358. March
1963. |
|
[Reynolds,
92] |
REYNOLDS
D.A.,
A gaussian mixture modelling approach to text independent speaker
identification. A thesis, Georgia Institute of Technology. August 1992. |
|
[Reynolds,
94a] |
REYNOLDS
D.A.,
Experimental evaluation of features for robust speaker identification.
IEEE Transactions on ASSP, n° 2 (4), pp 639-643. 1994. |
|
[Reynolds,
94b] |
REYNOLDS
D.A.,
Speaker Identification and Verification using gaussian mixture models. In
Workshop on Automatic Speaker Recognition and Verification, pp 27-30. Martigny
(Switzerland). April 1994. |
|
[Reynolds,
95] |
REYNOLDS
D.A.,
Speaker Identification and Verification using gaussian mixture speaker
models. Speech Communication, n° 17(1-2), pp 91-108. August 1995. |
|
[Reynolds,
96] |
REYNOLDS
D.A.,
The Effects of handset variability on speaker recognition performance :
experiments on the switchboard corpus. In Proc. ICASSP 96, Philadelphia,
USA. May 1996. |
|
[Rosenberg,
76] |
ROSENBERG
A.E.,
Automatic speaker verification, a review. Proc. IEEE, n° 64(4), pp 475-487. 1976. |
|
[Rossi, 89] |
ROSSI M., De la quiddité
des variables. In Variabilité et spécificité du locuteur : études
et applications, pp 78-86. Marseille Luminy, France. Juin 1989. |
|
[Rudasi, 91] |
RUDASI
L., ZAHORIAN S.A.,
Text independant talker identification with neural networks. In
Proceedings ICASSP 91, pp 389-392. Toronto (Canada). 1991. |
|
[Sambur,
75] |
SAMBUR
M.R.,
Selection of acoustic features for speaker identification. IEEE
Transactions on ASSP, n° 23(2), pp 176-182. April 1975. |
|
[Savic,
90] |
SAVIC
M., GUMPTA S.K.,
Variable parameter speaker verification system based on Hidden Markov
Modelling. In Proceedings ICASSP, pp 281-284. New-Mexico (USA). 1990. |
|
[Schmidt,
97] |
SCHMIDT
M., GOLDEN J., GISH H.,
GMM sample statistic log-likelihood for Text independent speaker
recognition. In Proc. Eurospeech 97, Rhodes, Greece. September 1997. |
|
[Setlur,
95] |
SETLUR
A., JACOBS T.,
Results of a speaker verification service trial using HMM Models. In
Eurospeech 95, pp 639-642. Madrid (Spain). September 1995. |
|
[Soong,
85] |
SOONG
F., ROSENBERG A., RABINER L., JUANG B., A vector quantization approach to speaker
recognition. In Proc. ICASSP 85, pp 387-390. 1985. |
|
[Soong,
86] |
SOONG
F., ROSENBERG A.,
On the use of instantaneous and transitional spectral information in
speaker recognition. In
Proc. ICASSP 86, pp 877-880. 1986. |
|
[Thevenaz, 95] |
THEVENAZ
P., HUGLI H.,
Usefulness of the LPC-residue in text-independent speaker verification.
Speech Communication, n° 17(1-2), pp 145-158. August 1995. |
|
[Tishby,
91] |
TISHBY
N.Z.,
On the application of mixture AR HMMs to text-independent speaker
recognition. In IEEE Transactions on Signal Processing, vol. 39, pp
563-570. March 1991. |
|
[T-Netix] |
T-NETIX Inc., T-NETIX. Adresse
Internet : |
|
[Van
den Heuvel, 94] |
VAN
DEN HEUVEL H., RIETVELD T., CRANEN B., Methodological aspects of segment and speaker-related variability. A
study of segmental durations in Dutch. Journal of Phonetics, n° 22, pp
389-406. 1994. |
|
[Van
Vuuren, 96] |
VAN
VUUREN S.,
Comparison of Text independent speaker methods on telephone speech with
acoustic mismatch. In Proc. ICSLP, Philadelphia, USA, pp 1788-1791. 1996. |
|
[Vnunet, 2000] |
VNUNET.FR, La Connexion
Informatique, Adresse Internet : http://www.vnunet.fr/VNU2/actualite/page_article1.htm
? |
|
[Wang,
93] |
WANG
H.C., CHEN M.S., YANG T.,
A novel approach to speaker identification over telephone networks. In
Proc. ICASSP 93, Minneapolis, USA, pp 407-410. 1993. |
|
[Wassner,
96] |
WASSNER H., Etude sur la
paramétrisation du signal en Traitement Automatique de la Parole, Mémoire
Industriel ESIEA effectué ŕ l’IDIAP. Février 1996. |
|
[Wenndt,
97] |
WENNDT
S., SHAMSUNDER S.,
Bispectrum features for robust speaker identification. In Proc. ICASSP
97, Munich, Germany, pp 1095-1098. 1997. |
|
[Wolf,
92] |
WOLF
J.,
Efficient acoustic parameters for speaker recognition. The Journal of the
Acoustical Society of America, pp 2044-2056, n° 51(6). 1972. |
Vous avez besoin d'évasion ?!?
Alors consultez mon autre site web qui contient l'ensemble de mes carnets
de voyages ,
mais aussi un méta-moteur de recherche pour trouver,
pour vos vacances, un séjour au meilleur prix !
Copyright © 2001 GIPP Info